There is an ongoing (and interesting) discussion on the API-craft mailing list revolving around designing new media types for enabling hypermedia APIs primarily for programmatic consumption. As some folks may know, I like to use HTML as the media type for my hypermedia APIs. Steven Willmott opined:
I think the problem isn't "why not HTML" it's "why HTML" - if you strip out all the parts of HTML which are to do with rendering things for presentation you're left with almost nothing at all:
- <a>
- <h1>, <h2>, <h3> ... (as nesting)
- <ul><li>
- <ol><li>
- <p> maybe (as a kind of separator) - or <div> ...
and even some of these are marginal. There is useful stuff around encodings, meta-data etc. but pretty much everything else is redundant.
I thought this raised such an interesting implicit question, and I get asked about this enough that I thought it warranted a longer response. There are actually a variety of reasons I prefer using HTML:
- rich semantics
- hypermedia support
- already standardized
- tooling support
Rich Semantics
I've heard many folks say that HTML is primarily for presentation and not for conveying information, and hence it isn't suitable for API use. Hogwash, I say! There are many web experts (like Kimberly Blessing) who would insist that markup is exactly for conveying semantics and that presentation should be a CSS concern. People seem to forget that web sites actually worked before CSS or Javascript was invented! I rely on this heavily for my HTML APIs.
Now don't get me wrong--I'm not advocating a return to 1995; Javascript, CSS, and HTML advances have clearly afforded richer user experiences. But that doesn't mean your HTML API needs to serve up or depend on CSS or Javascript any more than clients need to execute it, necessarily. Just because the media type can express things you don't need or want doesn't make it a bad media type for your use--this is confusing the content for the media type.
So let's get to specifics. From a semantic and informational point of view, there are whole segments of the HTML spec that I've found useful for expressing data structures. We obviously have lists (<ol>), bags (<ul>), and maps (<dl>). Raw XML doesn't have any of these, and JSON can't distinguish lists from bags and is constrained to use strings as map keys. We get encapsulation or grouping via ancestor inclusion or explicitly with <div>. We get 2-dimensional data layouts via <table>, and in fact something even more general than a 2-dimensional array via @colspan and @rowspan.
But more powerfully, with the <a> tag, we have the ability to represent arbitrary data structures, even circular ones (which tree-structured media types like XML or JSON cannot represent). In fact, we can even representdistributed data structures (which, arguably, is what the Web as we know it is--a giant distributed data structure). This is amazingly powerful, and for comparable expressiveness in a different media type, you'll have to define conventions for all these things.
Now, let me just take a run through the HTML5 spec and identify which elements are useful or not useful from an API point of view:
- <html>
- required, so moot
- <head>
- useful for overall representation metadata, especially via <link> and <meta>
- <title>
- if you have a string that could be construed as a name for the whole representation, why not put it here?
- <base>
- useful for unambiguously supporting relative links
- <link>
- one of the key hypermedia controls, see the "Hypermedia Support" section below
- <meta>
- useful for arbitrary data annotations
- <style>
- Okay, I'll grant that this one is not as important for machine-to-machine (m2m) consumption, but it comes into play under the "Tooling Support" section below.
- <script> and <noscript>
- Arguably, this is useful for implementing code-on-demand, but I'll grant that my current m2m use cases aren't this advanced yet.
- <body>
- necessary for separating metadata in <head> from actual data
- <section>, <article>, <aside>, <h1>-<h6>, <hgroup>, <header>, <footer>, <blockquote>
- These are primarily useful for describing content meant for human consumption, and while I have not had cause to use these myself, they would clearly have an important place to play if data payloads had this structure, e.g., in the API for a content management system (CMS). That said, I'm happy to lump these into "not useful" for the sake of argument.
- <nav>
- For m2m, I'm not sure there's much benefit to this over <link>s in the <head>, although there's room for more expressiveness here. Let's say, YAGNI here.
- <address>
- If you have data that's an address, why not mark it as such? Seems like a not-that-unusual circumstance.
- <p>, <pre>, <span>
- These are fine containers for arbitrary string data with slightly different semantics, particularly around whether whitespace is significant or not, and whether content may reasonably flowed when presented in a UI. However, these offer the ability to have rich content if desired as well.
- <ol>, <ul>, <dl>, <li>, <dt>, <dd>, <div>
- As mentioned above, necessary for representing data structures.
- <figure>, <figurecaption>
- Arguably not needed for m2m interactions.
- Text-level semantics like <i>, <b>, etc.
- Not useful immediately for m2m interactions, but rather to allow rich payloads. Arguably, a JSON-based media type could carry HTML markup in its strings, but then there is an impact on tooling and visibility, which we'll discuss in tooling support below.
- <img>
- I've seen many APIs that send around links to thumbnails, for example. Clearly useful.
- <iframe>, <embed>, <object>, <canvas>, etc.
- Similar to the discussion of <script> above, our m2m interactions are not advanced enough to take advantage of these (yet).
- <audio>, <video>
- Similar to images, allows for discussion of multimedia as first-class objects.
- <form> et al.
- Perhaps the single biggest reason to use HTML is its support for parameterized navigation via forms. See "Hypermedia Support" below.
Looking back across this list, sure, there's a lot of things that might not be immediately useful, but there's actually quite a large portion of HTML that offers semantics I'd immediately find useful in a programmatic API. We basically get to reap the benefit of many years of evolution in HTML, where its expressive power has grown and been refined over the years. You'll end up repeating most of the HTML standardization process to get a new media type up to the same level of expressiveness.
On top of that, however, are facilities for describing application-domain specific semantics, namely through the use of microdata and/or RDFa--all the "semantic web" stuff. I don't have to create a new semantic ontology for my application domain; I can leverage and/or enrich my markup with Dublin Core or Schema.org.
In short, from a data description point of view, HTML and its associated standards give me all the tools I need to describe almost anything I could imagine, and those facilities are all off-the-shelf from my perspective.
Hypermedia Support
HTML offers <a>, <link>, and <form> as obvious examples of hypermedia controls. In fact, the use of <form> to support parameterized navigation (where the client supplies some of the information needed to formulate a request) fairly well sets HTML apart from most existing standard (in the sense of being registered in the IANA standards tree for media types) media types. While currently this construct is not as powerful or expressive as it could be--c.f. only supporting GET and POST for methods--it's actually enough to get by, and is certainly sufficient for a RESTful system (if you care about qualifying for the label). Furthermore, there are ongoing efforts within the HTML5 standards process to address this.
(As an aside, it's worth noting that <audio>, <video>, <iframe>, and <img> are also hypermedia controls).
Already Standardized
HTML is shepherded by an existing open standards process and a large community of experts, which means it has all the social machinery for ongoing support and evolution. More than that, however, HTML has had the opportunity to be battle-hardened with real world use for decades, including the documentation that comprises its specification. This is huge, because in documentation I can talk about "following links" and "submitting forms" without getting into details about how to construct those HTTP requests, because someone has already taken the trouble of writing that all down, including all the nasty corner cases. I'm lazy--I don't want to define and write down a bunch of rules that solve the same problems reams of experienced people that came before me have already solved.
Furthermore, due to its ubiquity, EVERYONE AND THEIR BROTHER understands HTML and lots of those people can write valid markup without consulting the HTML5 spec (of course, there are also lots who only think they can write valid markup without looking at the spec!). While developers may not be used to using HTML to power APIs, they can nonetheless look at an API response and understand what's going on. This is a huge advantage.
More importantly, HTML is already all over the Web, and there are both human and machine participants consuming it. If I'm starting from an API, then it's entirely possible that someone from the "human-oriented" Web might link to my API, and presto, they can use it, because:
human + browser = client for my HTML API
Similarly, if I'm writing a client, and it can parse HTML (and especially if it can parse RDFa or microdata), then there's a chance it could be pointed at the human-oriented Web and find it can do something useful. But if that client can't parse HTML, then it has no hope of accessing all the existing HTML content on the web.
The phrase here is "serendipitous reuse". The human stumbling onto my API will likely not find it pretty or well-designed, but they may still be able to use it. The programmatic client trolling through web sites will likely ignore half the stuff it downloads, but it still may find something useful (obviously Google has been able to do this). If I find my API is being visited by humans, too, I can add a link to a stylesheet and perhaps download a javascript client, and present them a more usable interface without bothering my programmatic clients that much. Similarly, if my human-oriented website decides it wants to serve programmatic clients too, it can always add semantic tagging in the meantime, and evolve elsewhere.
Tooling Support
Before we get too far into this, let's talk for a minute about the relationship of HTML to XML. Both are flavors of SGML, although the sets of valid documents each can describe are overlapping and distinct. Specifically, there are valid HTML documents that aren't valid XML documents and vice versa, but there are documents that are both valid HTML and valid XML. Then there's XHTML, which is always valid XML but not always valid HTML (depending on the versions). Thus, the relationship is:
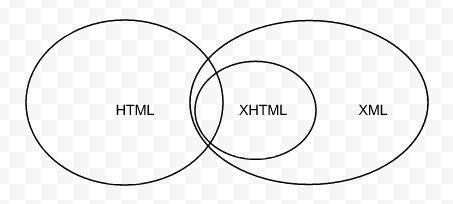
In particular, I find that I can often use markup for my API that actually sits in the intersection of all three. My programmatic clients can ask for application/xhtml+xml, and I can give it to them, and browsers can ask for text/html, and I can give them the exact same bytes with a different Content-Type. If my client wants to use the ubiquitous and available XML parsing and handling libraries out there, great! If they want to be more robust and parse the full subset of HTML, great! And yes, there are full HTML parsing libraries (not XML parsing libraries) in most programming languages, for example: Python, Ruby, Javascript, Perl, PHP, C, and Java.
Now, I will grant that most of these give you a DOM, and not much support above that, so you are endlessly and tediously traversing descendents and siblings in for loops, examining attributes to find what you're looking for. We do have an example, though, that shows manipulating a DOM need not be hard or tedious, and that is likewise ubiquitous: JQuery. And indeed, you can use JQuery selector syntax in other languages, too, like Java or Python. So most of what you actually need for manipulating HTML programmatically in a client already probably exists.
On the server side, we are up to our ears in webserver frameworks that serve up HTML, and IDEs and practices that are set up to optimize developing, testing and debugging them. It's sure nice to load your API up in a browser and play with it. A human plus a browser is a fully-capable client of your HTML API, regardless of what programmatic clients you may be targeting. I can look at the requests and responses over the network and examine the markup in detail in Chrome's developer tools. Many frameworks written for compiled languages like Java can even hotload markup template changes on the fly without recompiling. Plus you can wave a stick and hit thousands (perhaps millions) of developers who are already familiar with all of these technologies.
But what about...?
Domain-specific media types. They're so concise! True; you'd have to work a little harder to represent a blog in HTML than in Atom or RSS, or to represent contact information in HTML rather than in vcard. If there's a domain-specific media type out there for what you're doing, great! Use it--that's what it's for! But I find I work in a world where the application domain is evolving rapidly with new concepts and new features, or where application domains are mixed and mashed up. Many domain-specific media types don't accommodate this well. Imagine trying to write a media type to document Facebook's functionality. You'd end up needing to change the spec daily! That defeats the purpose of having off-the-shelf libraries help you along for the parts that aren't changing much. Or wait--you could build a media type that was so flexible that it could express almost any application...oh.
Bloat. JSON is way more concise, and that really matters for mobile apps. I've heard this so many times that I'm going to have a hard time not being snarky here, so be warned. First off, if representation size or parsing speed is that critical, I'd suggest using a binary format instead, like Protocol Buffers or Avro. What's that? You don't want to use a binary format because it's not human readable? Ah, so you are willing to give up some efficiency to trade off for other things. I see.
But let's get down to some facts here. I often see the following argument presented:
"Here's my sweet JSON representation, only 122 bytes!"
{ "contacts" : [
{ "firstname" : "Jon", "lastname" : "Moore" },
{ "firstname" : "Homer", "lastname" : "Simpson" }
] }"And here's the bad, old, ugly XML HTML representation. It's 266 bytes, 118% bigger!"
<html>
<body>
<ol class="contacts">
<li><span class="firstname">Jon</span>
<span class="lastname">Moore</span></li>
<li><span class="firstname">Homer</span>
</li>
</ol>
</body>
</html>
<span class="lastname">Simpson</span
>"Ergo, HTML is more bloated than JSON."
There are a couple of observations to make here. First, both of these would fit quite comfortably in a single TCP packet carried in a single 1500 byte Ethernet MTU frame, unless you've got a LOT of headers, in which case, start looking there for bandwidth savings first! So you're not going to notice the difference in practice.
But we're building an HTTP-powered API, right? And we're using compression, right? If I gzip those two files, the gzipped JSON version is 103 bytes and the HTML version is 150 bytes. Now the HTML is only 45% bigger, not 118% bigger. But still bloated, right? Wait, there's more.
These are really small files. Compression algorithms like Huffman coding are based on repeatability of the occurrence of certain strings of bytes, so the compression rate is based on how big and how common those repeated strings are. Well, it turns out that what you call "bloat", gzip calls "compressable." The longer the document, the better it compresses, and the closer gzip will get to the information theoretic minimal representation. Let's see this in action, and with a real API, rather than a toy example. Here's a sample JSON response from the Twitter API, and here's anequivalent XML response, also from the Twitter API. Finally, here's turning it into an HTML-style response.
These samples are, respectively, 44265 bytes (JSON), 64493 bytes (XML), and 40252 bytes (HTML). Wait, what? The HTML representation is the smallest? How is that even possible? I did take the liberty of eliding blank properties, using HTML5 data attributes, and putting true boolean properties as @class values (and leaving off false boolean properties), which I assert are all common HTML idioms. But compare the source gists linked above and decide for yourself.
Now let's gzip them: 7366 bytes (gzipped JSON), 7855 (gzipped XML), 7287 (gzipped HTML). This is only a size difference of 7% from smallest to largest, and even if you don't consider my HTML version comparable, you can see that gzip compression is removing a lot of the differences.
Now, don't get me wrong, JSON is a fine format, and I use it regularly. There are lots of good reasons to use it, but claiming that it is more economical on the wire, while possibly true, is probably not true by enough to make it a deciding factor (and if that really is a deciding factor, you probably want to go to binary formats anyway).
Summary
So what this all boils down to is that HTML offers me quite a lot of convenience as a hypermedia-aware, domain-agnostic media type. I have lots of off-the-shelf tooling, including getting my first client for free (the browser), and from a documentation point of view, between the HTML and HTTP, there's a whole lot of mechanics I don't have to discuss. In fact, if I'm using microdata, I don't even necessarily need to write much down about the particular application domain, at least from a vocabulary point of view. It might even be sufficient to document an HTML API just by listing out:
- URL of the entry point(s)
- link relations used (with pointers to their definitions elsewhere!), and important <form> @class values and <input> @names of importance (I think forms need parameterized link relations to do this a little more formally, but we don't quite have those yet)
- pointers to the microdata definitions of importance (again, elsewhere).
That's not a lot to have to write down.
Relax and enjoy, don't be rush.
ConversionConversion EmoticonEmoticon